#63 - Luận giải về LLM và lợi thế cạnh tranh của con người
Đào sâu một chút vào cách hoạt động của LLM, và một số quan điểm về những thứ bạn vẫn có thể làm tốt hơn so với chúng.


Nhắm mắt lại và tưởng tượng rằng bạn đang sống cách đây khoảng 2 triệu năm. Mặt trời đã hoàn toàn xuống núi, và bạn không thể nhìn thấy bất cứ thứ gì trong màn đêm. Nhân loại vẫn cần thêm tầm 500,000 năm nữa trước khi ai đó khởi tạo được ngọn lửa đầu tiên. Lụm cụm trong bóng tối, bạn không biết có một con sói bụng đói cồn cào nào đang mai phục, hay có con rắn độc nào đang lườn bò quanh đây không. Đối diện với sự bất định, cơ thể của bạn được đẩy vào trạng thái cảnh giác cao độ.
Không ai biết chính xác con người sống như thế nào trước khi có lửa, nhưng chắc tổ tiên chúng ta cũng đầy ắp nỗi âu lo và thấp thỏm trong bóng đêm. Không chỉ đơn thuần là một cảm giác bất định, mà là đó là cảm giác khi đối diện với sự bất định. Bộ não của con người khao khát sự kiểm soát, bởi lẽ sự sinh tồn của cá thể và chủng loài phụ thuộc vào việc điều khiển được môi trường xung quanh. Sự bất định đe dọa khao khát đấy, nên chúng ta thường xuyên sợ hãi những thứ không biết và không điều khiển được.
Quay nhanh kim đồng hồ đến thế giới ngày nay. Từ lúc ngành công nghiệp đèn điện hình thành, con người không còn sống trong lo lắng mỗi khi đêm về nữa. Nhưng cứ mỗi vài thập kỷ đều xuất hiện những nỗi bất định mới làm cho nhiều người sợ hãi và thao thức giống như 2 triệu năm về trước. Hiển nhiên, sự bất định gần đây nhất chính là AI.
Nỗi sợ này không phải mình tự nghĩ ra, mà từ những câu hỏi đến từ các bạn học viên BPM cũng như trong vòng tròn của mình. Ngoài điểm chung là mọi người đều lo lắng, thì mình thấy đa phần chúng ta vẫn chỉ sợ sệt theo một cách "bản năng". Thay vào đó, chỉ cần cố gắng tìm hiểu sâu hơn một chút về cơ chế hoạt động của AI, thì nhiều chuyện sẽ trở nên tường minh hơn. Mình nghĩ rằng tri thức giống như một ngọn lửa, hiểu biết về một thứ gì đó sẽ khiến con người đỡ sợ hơn.

Với tinh thần đó, bài viết này mình muốn luận giải một cách tương đối chi tiết về LLM và nêu ra một số quan điểm về lợi thế cạnh tranh của con người so với AI.
Sau đây là hai nội dung chính:
- Luận giải về LLM, mà cụ thể là Transformer. Đây là phần chính, cũng là phần dài và chi tiết nhất. Khó để nói chúng ta còn làm được gì hơn LLM khi chưa nói về bản chất của chúng.
- Con người đang làm được gì hơn LLM. Đây là phần quan điểm, mình sẽ dùng những kiến thức được trình bày ở phần đầu để về một vài pattern mà con người vẫn có khả năng làm tốt hơn.
(1) Những kiến thức được trình bày trong đây không phải là sáng tạo của mình, mà đến từ nhiều bộ não tinh hoa của nhân loại. Mình chỉ đóng vai trò tổng hợp và trình bày chúng theo cách mà mình hy vọng là dễ hiểu.
(2) Ngoài ra, bài viết này khá dài (~10,000 từ) và mình có cố gắng giải thích các phương trình trong LLM. Bạn có thể lưu lại rồi khi nào ở trong trạng thái tinh thần phù hợp thì đọc nhé! Mình nghĩ bạn nên đọc trên web thì tốt hơn là trên mobile cho nó đỡ mỏi tay mỏi mắt.
(3) Có những kiến thức và khái niệm mình lược bỏ khỏi bài viết nhằm thu hẹp phạm vi của nó lại. Nếu bạn có cách để mở rộng liên kết chúng lại để đọc giả dễ hiểu, thì hãy để lại comment nhé!
Khi bàn về AI, đa phần chúng ta đang nói đến LLM. Để hiểu được LLM, chúng ta cần hiểu về kiến trúc Transformer - được giới thiệu lần đầu trong paper có tên "Attention is all you need" vào năm 2017.
Kiến trúc Transformer chính là thứ mở đường cho những mô hình GPT đầu tiên rồi sau đó cách mạng hóa cả nền công nghiệp AI nói riêng và mảng công nghệ nói chung. Tuy các mô hình LLM ngày nay có nhiều bước tối ưu hóa hơn, nhưng về bản chất chúng vẫn dùng một dạng kiến trúc Transformer. Nắm được kiến trúc này sẽ giúp chúng ta hiểu hơn về cách mà các mô hình như ChatGPT, Claude hay Gemini có thể mô phỏng được trí thông minh giống như con người.
Trong bài viết này, khi mình nói về AI hay LLM, thì mình đang nói cụ thể về Transformer. Tuy còn những phạm trù khác trong Deep Learning hay trong mảng AI nói chung, mình xin phép sẽ giữ sự tập trung vào LLM/Transformer.
Kiến thức nền tảng
Mình sẽ lướt sơ qua một số kiến thức nền tảng để chúng ta xây dựng intuition để hiểu về bản chất của LLM/Transformer tốt hơn.
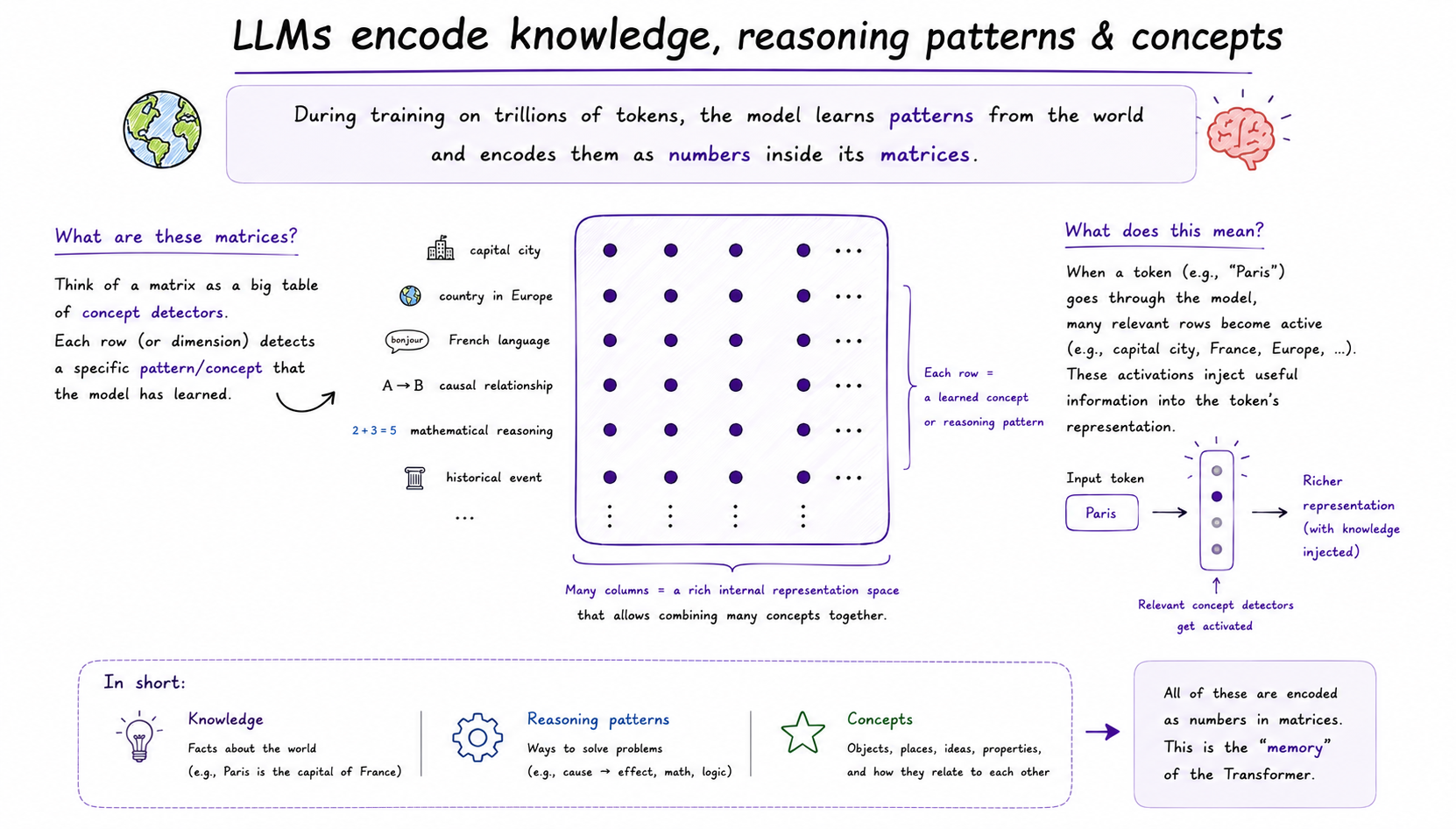
- (1) LLMs mã hóa các pattern về thế giới từ dữ liệu training. Về lý thuyết, LLMs được train để dự đoán token tiếp theo. Bài toán này nghe có vẻ đơn giản, nhưng để dự đoán token tiếp theo được tốt, LLM phải học được các mô hình nhân quả nằm chìm ở bên trong dữ liệu. Đây là lý do mà ChatGPT hay Claude lại có vẻ "thông thiên văn, tường địa lý" đến vậy.
- Con người chúng ta mã hóa được các hiện tượng cũng như mối quan hệ nhân quả vào trong câu từ nhằm phục vụ mục đích giao tiếp. Nếu không, chúng ta sẽ không hiểu được câu: "Em bé khóc. Mẹ ẵm nó lên dỗ."
- Rõ ràng tồn tại một mô hình nhân quả ở trong đó việc một em bé nào đó khóc sẽ dẫn đến hành vi dỗ dành của người mẹ (và đọc giả sẽ tự ngầm định luôn "mẹ" ở đây chỉ đến mẹ của đứa bé chứ không phải bất kỳ người mẹ random nào).
- LLM được huấn luyện dựa trên hàng triệu triệu điểm dữ liệu ngôn ngữ mà bên trong chúng mã hóa những quy luật, mối quan hệ, định nghĩa, khái niệm về thế giới, và chúng dần học cách mã hóa những pattern đó dưới dạng các con số trong network. Cơ chế này mô phỏng công năng, nhưng không hẳn sát với cách não bộ con người thật sự học (predictive coding là một cơ chế khác có vẻ gần hơn).
- (2) Token là đơn vị được nhỏ nhất LLMs xử lý ở đầu vào cũng như ở đầu ra. Cách hiểu sau đây nó không chính xác 100%, nhưng nó gần đúng và đủ hữu dụng: bạn có thể xem mỗi token như một từ ở trong câu. Khi bạn đưa cho ChatGPT hay Claude một câu prompt, từng từ đơn lẻ ở trong prompt đó có thể xem như một token.
- (3) LLMs xử lý tất cả tokens song song chứ không tuần tự. Trái với việc LLM dự đoán và output ra từng token đơn lẻ, chúng xử lý các tokens đầu vào song song. Trong bài viết này, mình sẽ cố gắng break down từng phép biểu diễn cũng như biến đổi để xây dựng được intuition, nhưng bạn nên tưởng tượng những phép biến đổi đó diễn ra song song trên tất cả tokens. Để làm được điều này, thì chúng ta phải biến đổi tokens thành một dạng số để máy tính có thể xử lý song song hiệu quả.
- (4) LLMs biểu diễn token và xử lý chúng dưới dạng số, cụ thể là ma trận số. Nếu prompt của bạn có 100 từ (100 tokens), thì mỗi token sẽ được số hóa thành 1 embedding vector. Mỗi embedding vector sẽ có độ dài 8192 con số, và thứ Transformer sẽ xử lý đầu vào là một ma trận chứa các embedding vector này, với chiều không gian là 100 x 8192.
- Ma trận này chính là thứ sẽ được Transformer tính toán biến đổi, để cuối cùng ở đầu ra sẽ là 1 embedding vector có độ dài 8192. Vector này sẽ được chuyển về lại thành dạng token mà con người đọc hiểu được - đây chính là những câu từ bạn thường thấy ChatGPT, Claude hay Gemini output ra. Trong câu chuyện trên, mình có nhắc đến embedding vector, đó là gì?
- (5) Embedding vector là dạng biểu diễn số của một token trong không gian đa chiều. Càng đi xuống bản chất ở tầng thấp nhất của máy tính, chúng ta càng thấy tất cả chỉ là những con số. Nếu token là một từ trong câu, thì nó cần được biến đổi thành dạng số theo một cách nào đó để LLM có thể xử lý được. Đây là lý do tại sao chúng ta phải biến token thành embedding vector.
- Cơ chế để biến token thành embedding vector thì có nhiều, nhưng thứ quan trọng cần hiểu, đó là các embedding vector cho token không nằm ở tọa độ ngẫu nhiên. Vị trí tương đối của chúng trong không gian đa chiều đều có ý nghĩa.
- Thí dụ: embedding vector biểu diễn token "Coffee" sẽ gần với embedding vector cho token "Trà" hơn là embedding với vector cho token "Mèo." Với cùng một mô hình LLM, thì một token lúc nào cũng sẽ chỉ tương ứng với một embedding vector.
- Nếu khoảng cách giữa 2 vectors nó có ý nghĩa, thì làm thế nào thể hiện được khoảng cách này dưới dạng toán học? Chúng ta có thể dùng:
- Cơ chế để biến token thành embedding vector thì có nhiều, nhưng thứ quan trọng cần hiểu, đó là các embedding vector cho token không nằm ở tọa độ ngẫu nhiên. Vị trí tương đối của chúng trong không gian đa chiều đều có ý nghĩa.
- (6) Dot Product thể hiện độ tương đồng (similarity) của 2 vectors. dot product (thường thể hiện trong phương trình bằng dấu chấm) đo đạc mức độ giống nhau của 2 vectors trong không gian đa chiều. Lấy lại ví dụ trên, dot product của vector cho token "Coffee" và vector cho token "Trà" sẽ cao hơn là dot product giữa "Coffee" và "Mèo". Kết quả của dot product là một con số gọi là similarity score.
- (7) LLMs mã hóa các pattern học được từ dữ liệu dưới dạng ma trận số. Không chỉ token đầu vào được diễn tả dưới dạng vector chứa những con số như trên, mà Transformer còn phải học được những pattern từ dữ liệu training. Các pattern này cũng được trữ dưới dạng những ma trận con số.
- Về bản chất có thể xem Transformer là một cỗ máy thực hiện các phép biến đổi hình học để biến một ma trận con số (là những tokens đầu vào) thành một ma trận con số 1 cột (a.k.a vector), chính là token Transformer dự đoán tiếp theo.
Không chỉ các token đầu vào được biểu diễn dưới dạng vector số, mà trong quá trình huấn luyện, Transformer còn học được cách biến đổi những vector này thông qua hàng tỷ tham số được mã hóa trong các ma trận trọng số.
Nhìn từ một góc độ trực giác, Transformer có thể được xem như một cỗ máy thực hiện liên tiếp các phép biến đổi hình học trên không gian vector. Nó nhận vào một ma trận gồm các embedding vectors của những token trong câu, rồi từng bước biến đổi chúng thành những biểu diễn ngày càng giàu ngữ cảnh hơn.
Khi đi qua lớp Transformer cuối cùng, mỗi token sẽ sở hữu một vector biểu diễn đã hấp thụ thông tin từ những token xung quanh. Vector tương ứng với token cuối cùng sau đó được sử dụng để tính toán xác suất xuất hiện của token tiếp theo trong từ vựng.
Tổng quan về Transformer
LLMs, mà cụ thể là Transformer, mã hóa patterns học được từ dữ liệu dưới dạng các ma trận. Các con số trong ma trận này được tinh chỉnh trong quá trình training để mã hóa được các pattern về khái niệm, nhân quả nằm chìm bên trong ngôn ngữ của loài người. Các ma trận này chính là thứ Transformer sẽ sử dụng để biến đổi các token đầu vào, rồi xử lý chế biến chúng để output ra token tiếp theo.
Có hai dạng biến đổi chính ở trong kiến trúc Transformer:
- (1) Attention tìm kiếm và hòa tan thông tin từ các tokens liên quan vào một token. Thí dụ, vector cho token "trời" trong câu "Trời ơi!" và token "trời" trong câu "Bầu trời hôm nay xanh quá" ban đầu là giống nhau (đều là 1 embedding vector), nhưng thông qua cơ chế Attention, vector trong hai câu đó sẽ trở nên rất khác nhau do ngữ cảnh của các tokens liên quan cũng khác nhau. Attention biến một token embedding vector thành một token vector khác có nhiều thông tin hơn đến từ ngữ cảnh.
- (2) Feed-Forward Network (FFN) sử dụng output vector của Attention, rồi tìm kiếm và kích hoạt những khái niệm liên quan mà LLM đã học được (các khái niệm hay mối liên hệ này là các ma trận trọng số đã được học trong quá trình huấn luyện). Thí dụ, với cùng một token "trời", FFN sẽ truy xuất được các khái niệm về thời tiết trong câu "Bầu trời hôm nay xanh quá", hoặc khái niệm về cảm thán trong câu "Trời ơi!".
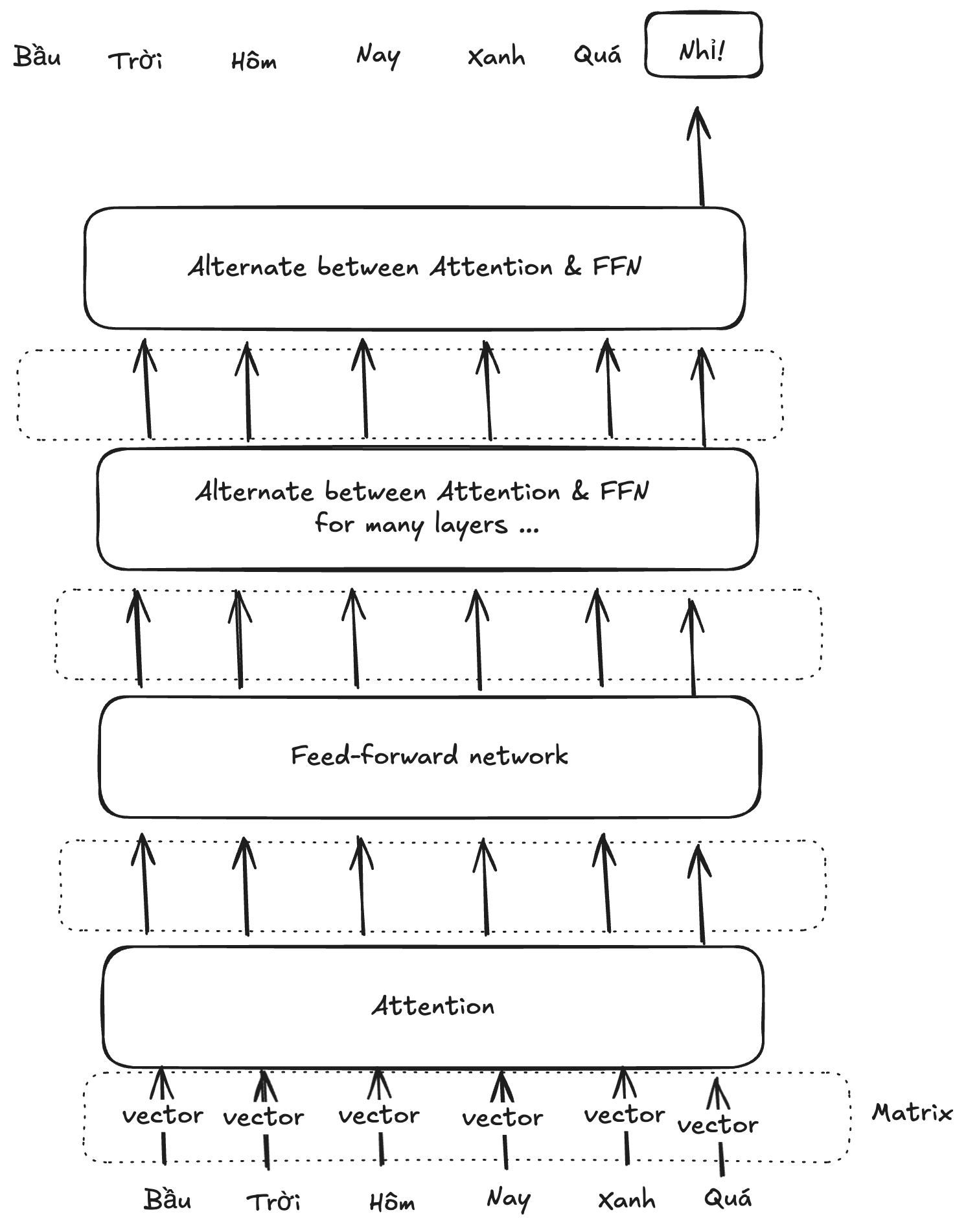
Hai dạng biến đổi này đan xen nhau: token vector đi qua Attention sau đó được biến đổi tiếp bằng FFN, thông qua nhiều lớp như vậy để cuối cùng output ra được một token vector đại diện cho token tiếp theo mà Transformer dự đoán.
Vậy Attention và Feed-Forward Network hoạt động như thế nào? Hãy đi vào cơ chế Attention trước, vì đây là phần có lẽ sẽ phức tạp nhất để xây dựng được intuition. Khi chúng ta qua được quả núi này rồi, thì phần FFN có thể sẽ dễ hiểu hơn một chút (một chút thôi 😁).
Cơ chế Attention
Tưởng tượng nếu ai đó nói với bạn một từ "xanh", thì bạn sẽ hiểu ngữ nghĩa như thế nào? Rất khó để biết được nếu không đặt nó nằm trong một bối cảnh cụ thể.
Giả dụ chúng có một câu hoàn chỉnh ("Hôm nay bầu trời xanh quá") đi nữa, thì câu hỏi tiếp theo, là bạn sẽ nên để ý đến từ nào? Trong tình huống này, từ "trời" là thứ bạn nên để ý nhất, bởi vì nó giúp chúng ta hiểu được "xanh" ở đây đang diễn tả một trạng thái thời tiết, chứ không phải tên một hảng xe công nghệ.
Nếu đứng ở góc độ phải hiểu ý nghĩa của từ "trời" trong câu trên, thì có thể bạn sẽ để ý nhất đến từ "hôm" và "nay", để hiểu được rằng "trời" đang là một khái niệm trong thì hiện tại, chứ không phải là một từ cảm thán. Ngược lại, nếu câu là "Hôm nay bị sao á trời" thì "trời" sẽ là có ý nghĩa cảm thán.
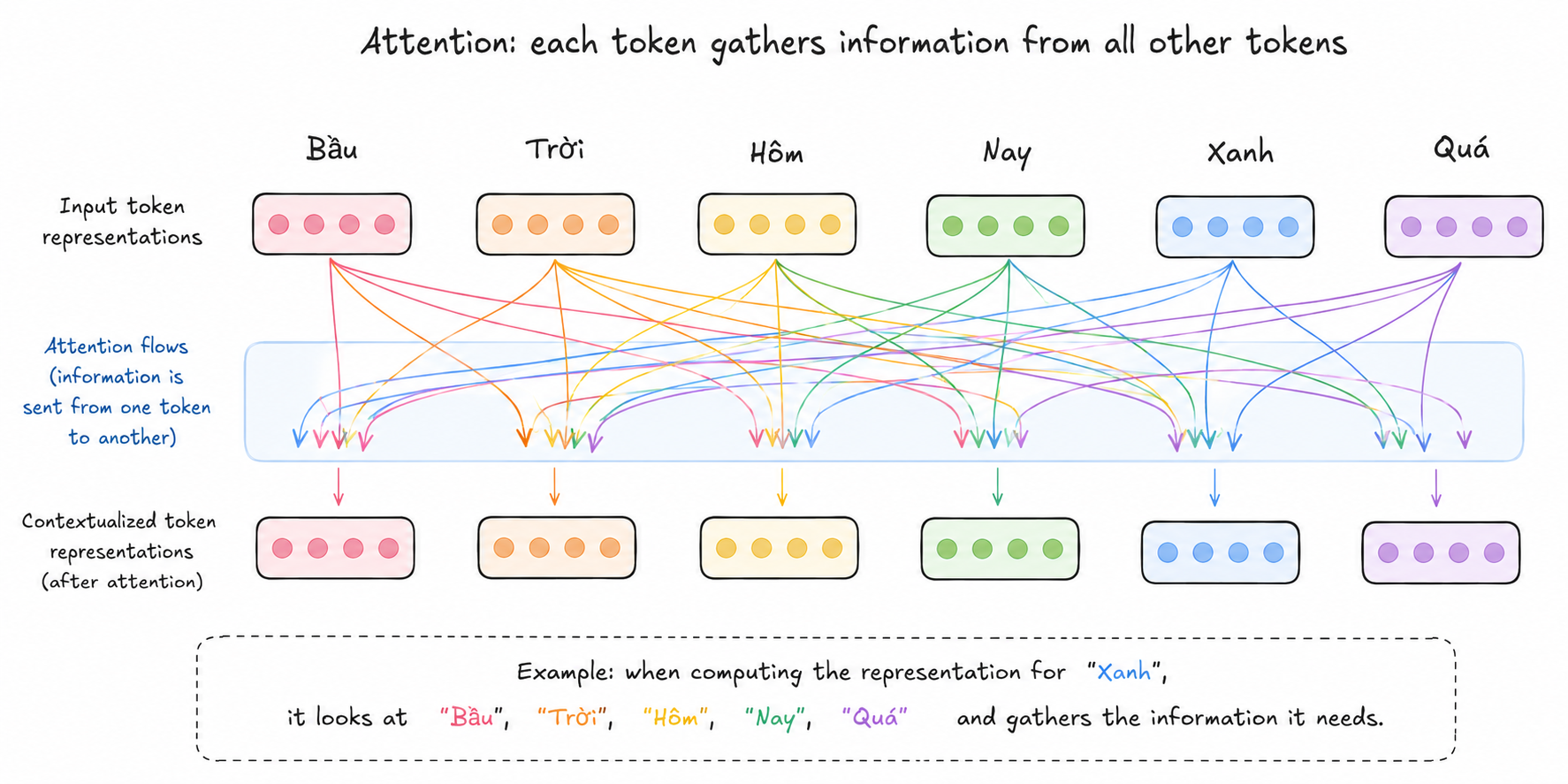
Attention làm dày ý nghĩa của một token từ các tokens khác
Nhưng đến đây xuất hiện một câu hỏi khác. Con người có thể đọc câu "Hôm nay bầu trời xanh quá" và gần như ngay lập tức biết rằng từ "xanh" nên chú ý đến từ "trời". Chúng ta làm điều đó một cách vô thức, nhưng máy tính thì không.
Đối với LLM, mỗi từ ban đầu chỉ là một vector gồm hàng trăm hoặc hàng nghìn con số. Nó không biết "trời" là bầu trời, cũng không biết "xanh" là màu sắc. Vậy làm thế nào để mô hình xác định rằng khi xử lý từ "xanh", nó nên chú ý nhiều đến từ "trời" hơn là từ "hôm" hay "nay"?
Để trả lời, mô hình cần một cách đo lường: với mỗi cặp token, một con số thể hiện mức độ mà token này nên để ý đến token kia. Con số đó gọi là Attention Score - score càng cao thì token càng đáng được để ý.
Sau khi một token (với embedding vector T1) xác định rằng nó nên chú ý đến một token khác (với embedding vector T2), thì cơ chế Attention sẽ lấy thông tin từ (T2), hòa nhập nó vào (T1) và cho ra một token vector mới (T1+) mà có ngữ nghĩa dày đặc hơn. Tương tự, nếu (T2) cũng cần để chú ý đến (T1), thì Attention sẽ lấy thông tin từ (T1) và biến đổi (T2) thành (T2+).
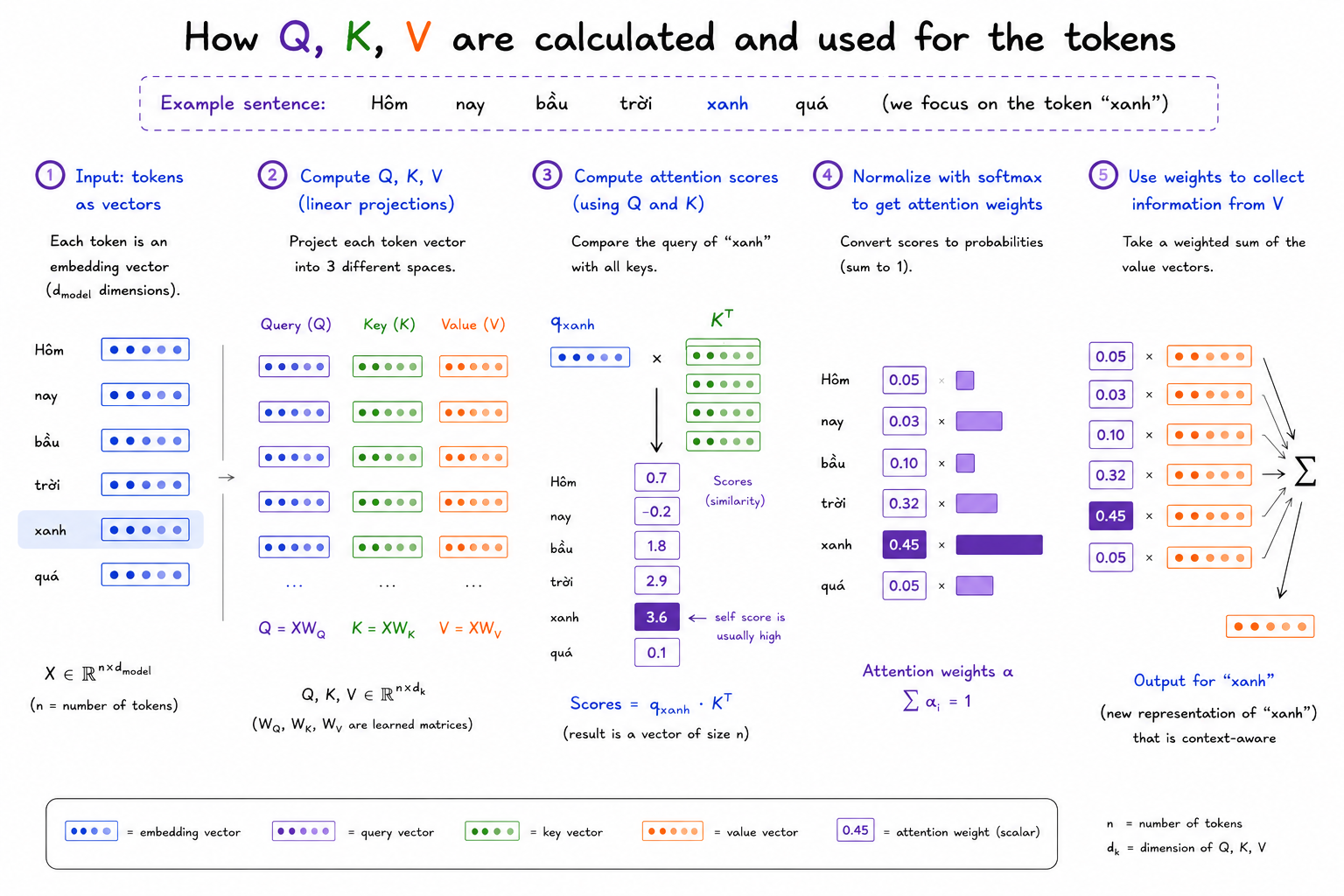
Toàn bộ cơ chế tính toán này, từ việc đo Attention Score cho đến việc dùng nó để tạo ra biểu diễn mới cho token, được gói gọn trong một phương trình duy nhất, trích từ paper "Attention is all you need":
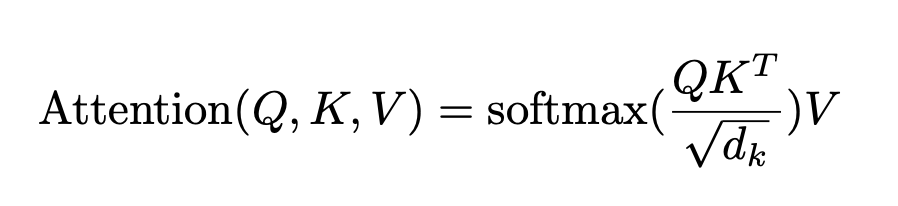
Đừng lo nếu bạn bắt đầu thấy lùng bùng. Khi nhìn vào một định nghĩa toán học như trên, chúng ta cần hình dung được bức tranh tổng thể trước, rồi mới diễn dịch từng chi tiết sao cho khớp với bức tranh đó.
Bức tranh tổng thể là: phương trình này thực ra làm hai việc nối tiếp nhau.
- Trước hết, nó tính xem mỗi token nên để ý đến những token nào (phần Q·K^T chính là Attention Score).
- Sau đó, nó dùng kết quả đó để gom thông tin lại và tạo ra một biểu diễn mới, giàu ngữ cảnh hơn cho token (phần nhân với V).
Attention làm dày ý nghĩa của một token qua ba lăng kính
Nhưng trước khi đi vào cách hai bước trong phương trình trên vận hành, có ba chữ cái cần được giải mã: Q, K và V. Khi học sâu hơn thì mình biết rằng đấy chính là ba vector khác nhau được tính toán từ cùng một token embedding vector, để thể hiện ba khía cạnh khác nhau.
Lúc đấy trực giác của mình đã đặt ra câu hỏi:
Tại sao lại cần đến ba vector riêng biệt cho mỗi token, trong khi mỗi token đã có sẵn một embedding vector rồi? Nếu chúng ta chỉ muốn biết hai token có gần nhau trong không gian vector không, tại sao không đơn giản dùng thẳng embedding vector để tính dot product, rồi ra similarity score luôn?
Câu trả lời nằm ở chỗ: một embedding vector đơn lẻ không thể đồng thời đảm nhiệm tốt ba vai trò chức năng khác nhau.
Thử tưởng tượng bạn là PM đang ngồi trong một buổi brainstorm với team. Ở đó, bạn phải đồng thời làm ba việc rất khác nhau:
- (1) Trong đầu bạn đang có một câu hỏi chưa được giải đáp: "Liệu approach này có ảnh hưởng đến timeline release không?" Đây là thứ bạn đang tìm kiếm từ người xung quanh, đây là câu hỏi/truy vấn (Query).
- (2) Đồng thời, CEO đang nhìn quanh phòng tìm người có thể đưa ra quyết định về scope. Mắt họ dừng lại ở bạn, vì title PM là tín hiệu để họ biết bạn là người phù hợp với câu hỏi của họ - đây là "dấu hiệu tìm kiếm" (Key) của bạn, thứ giúp người khác định vị được bạn.
- (3) Khi CEO hỏi "Chúng ta có nên cut feature này không?", bạn không trả lời "Tôi là PM" (ít nhất nếu bạn còn muốn có việc), bạn sẽ trả lời kiểu "Theo data thì feature này chỉ có 3% users dùng, cut đi được." Đây là Value - nội dung cụ thể bạn đóng góp khi được chọn, khác hoàn toàn với cái tín hiệu đã khiến người ta tìm đến bạn.
Ba thứ này xuất phát từ cùng một con người, nhưng phục vụ ba mục đích hoàn toàn khác nhau. Tương tự, Q, K, V đều được tính toán từ cùng một embedding vector - nhưng qua ba phép biến đổi riêng biệt, bởi vì không có một biểu diễn đơn lẻ nào có thể đảm nhiệm cả ba vai trò đó cùng một lúc.
Chính vì thế, mỗi embedding vector cần được nhìn qua ba lăng kính riêng biệt. Qw, Kw, Vw chính là ba lăng kính đó - ba ma trận trọng số mà LLM học được trong training, mỗi cái đảm nhiệm đúng một vai trò. Khi dùng Qw, Kw và Vw để biến đổi token embedding vector, về bản chất là nhân chúng với nhau, chúng ta có được Q, K và V.
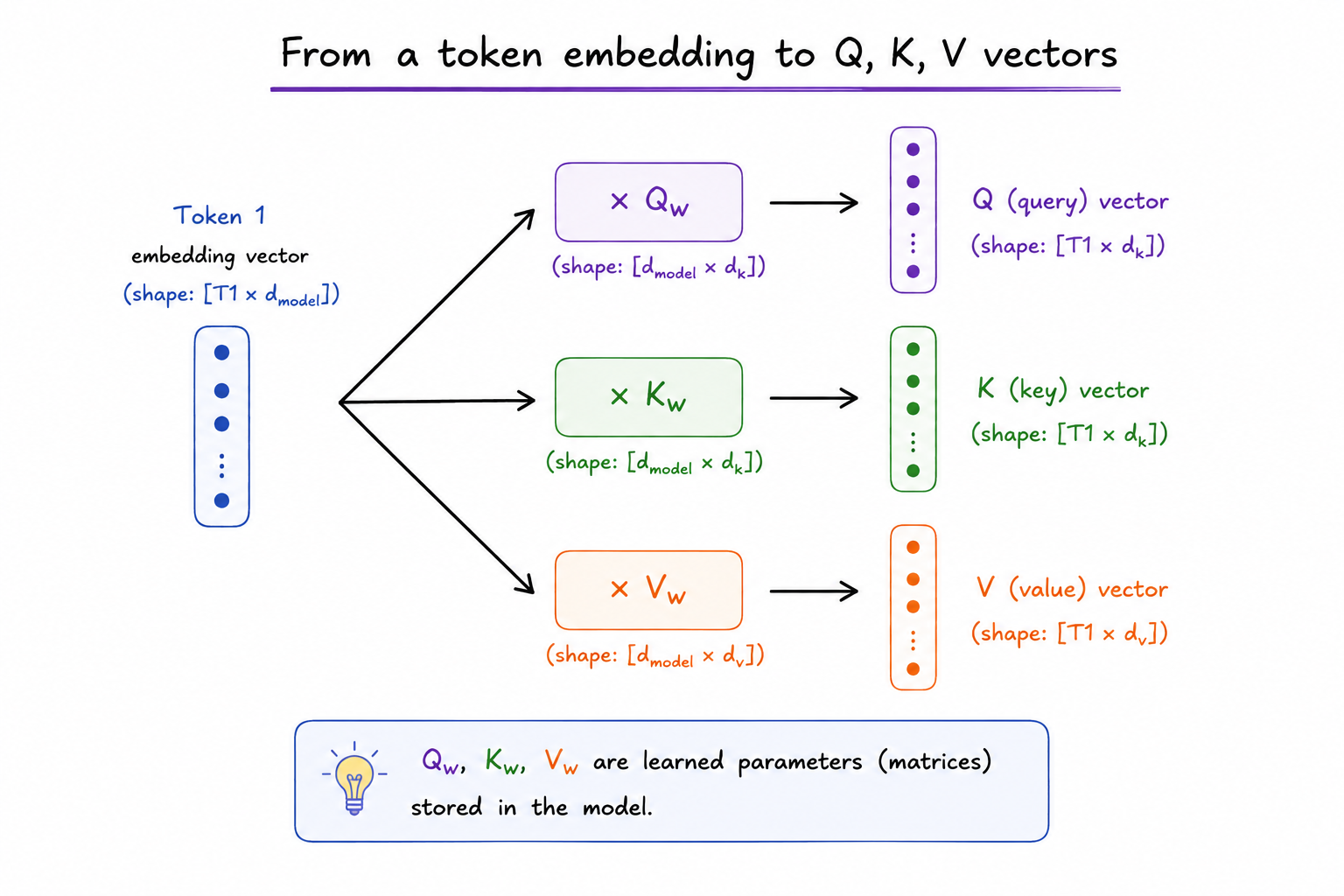
Như đã nói, Qw, Kw và Vw thể hiện 3 pattern câu hỏi khác nhau:
- (1) "Tôi cần thông tin gì từ các tokens khác?" Câu trả lời cho câu hỏi này chính là Q - đại diện cho các đặc điểm mà token sử dụng để tìm kiếm thông tin từ những token khác. Ma trận trọng số Qw được học từ dữ liệu training và xác định cách chuyển đổi biểu diễn của token thành một truy vấn tìm kiếm phù hợp.. Thí dụ, token "trời" trong câu "Hôm nay bầu trời xanh quá" đang tìm kiếm: "Có token nào xung quanh giúp tôi xác định mình đang là danh từ (bầu trời) hay thán từ (trời ơi) không?" - và nó sẽ tìm thấy "bầu" đứng ngay trước mình.
- (2) "Tôi có dấu hiệu nhận biết nào để các tokens khác tìm đến tôi?" Câu trả lời chính là K - đại diện cho các đặc trưng nhận diện của token. Ma trận trọng số Kw được học từ dữ liệu training để chuyển đổi biểu diễn của token thành một dạng mà các Query có thể đánh giá mức độ liên quan. Thí dụ, key của token "trời" quảng bá tín hiệu: "Tôi là danh từ liên quan đến thiên nhiên/thời tiết." Khi token "xanh" đang query "danh từ nào tôi đang bổ nghĩa?", key của "trời" sẽ khớp tốt - dẫn đến Attention Score cao giữa cặp "xanh" → "trời".
- (3) "Tôi sẽ cung cấp thông tin gì cho tokens khác nếu chúng cần?" Câu trả lời chính là V - đại diện cho thông tin mà token có thể đóng góp cho các token khác. Ma trận trọng số Vw được học dữ liệu training để chuyển đổi biểu diễn của token thành nội dung sẽ được truyền đi khi token đó được Attention lựa chọn. Thí dụ, khi "xanh" quyết định lắng nghe "trời", value mà "trời" thực sự gửi đi là: "Tôi là bầu trời - một thực thể vật lý, xuất hiện trong thì hiện tại, và 'xanh' đang mô tả trạng thái của tôi." Đây là lý do "xanh" sau Attention sẽ hiểu mình đang diễn tả thời tiết, không phải tên một hãng xe.
Với một token, query vector đại diện cho thông tin mà token đó cần và key vector đại diện cho dấu hiệu nhận biết để các token khác dễ tìm đến nó. Như vậy, chúng ta có thể trả lời câu hỏi
"Vậy tokens nào có thông tin mà tôi (một token) cần tìm kiếm?"
Bằng cách reframe nó dưới dạng:
"Vậy key vectors nào có độ tương đồng cao với query vector của tôi?"
Chúng ta thấy có thể tính được similarity score giữa 2 vector có bằng cách lấy dot product giữa chúng. Đây chính là lý do tại sao Q.K^T lại xuất hiện trong phương trình trên - chúng đại diện cho similarity score giữa query vector của một token và key vector của một token (có thể cùng token hoặc là query vector của một token khác).
Đến đây có hai vấn đề cần xử lý trước khi Q.K^T (Attention Score) dùng được.
- (1) Giá trị của Q·K^T bị ảnh hưởng bởi số chiều của vector. Vì dot product là tổng của rất nhiều phép nhân (mỗi chiều một phép), nên vector càng nhiều chiều, con số càng có xu hướng lớn - không phải vì hai token liên quan hơn, mà chỉ là hệ quả cơ học của việc cộng nhiều số hạng. Để con số phản ánh đúng mức độ liên quan thay vì kích thước vector, chúng ta chia cho căn bậc hai của dk (số chiều của vector) nhằm triệt tiêu ảnh hưởng này.
- (2) Sau khi chia, ta vẫn còn một dãy các score thô cho từng cặp token. Chúng ta cần biến cả dãy đó thành một phân bổ sự chú ý - các trọng số nằm trong khoảng 0 đến 1 và cộng lại bằng 1. Đây là việc của hàm softmax: nó nhận toàn bộ các score của một token rồi chuyển thành tỉ lệ phần trăm, ví dụ "xanh để ý trời 32%, hôm 5%, nay 3%...". Chính tính chất cộng-lại-bằng-1 này khiến chúng trở thành sự phân bổ, chứ không phải những con số rời rạc.
Sau khi softmax chạy xong, với mỗi token chúng ta có một bộ attention weights - ví dụ token "xanh" sẽ có: để ý "trời" 32%, "bầu" 10%, "xanh" chính nó 45%, "hôm" 5%, "nay" 3%, "quá" 5%. Những con số này trả lời được câu hỏi bao nhiêu, nhưng chưa trả lời được câu hỏi lấy gì.
Đây là lúc Value vector (V) phát huy vai trò. Với mỗi token mà "xanh" đang để ý, chúng ta lấy value vector của token đó - tức là phần thông tin mà token đó sẵn sàng đóng góp - rồi nhân với attention weight tương ứng. "Trời" đóng góp 32% nội dung của mình, "bầu" đóng góp 10%, "hôm" đóng góp 5%... Tất cả được cộng lại thành một vector duy nhất. Phép tính này chính là bước nhân với V trong phương trình.
Kết quả là một vector hoàn toàn mới - không phải embedding gốc của "xanh" nữa, mà là biểu diễn của "xanh" sau khi đã hấp thụ ngữ cảnh từ những token xung quanh theo đúng tỉ lệ sự chú ý. Token "xanh" bây giờ mang trong mình thông tin rằng nó đang đứng cạnh "bầu trời" trong thì hiện tại - và vì vậy nó đang diễn tả một trạng thái thời tiết, không phải tên một hãng xe. Đây chính là thứ Attention tạo ra: không phải một con số đo sự liên quan, mà là một biểu diễn mới của token giàu ngữ cảnh hơn, sẵn sàng được đưa vào Feed-Forward Network ở bước tiếp theo.
Cơ chế Feed-Forward Network (FFN)
Chúng ta vừa đi qua Attention - một phép biến đổi với mục đích giúp các token trao đổi thông tin với nhau. Tiếp tục ví dụ ở trên, thì token "xanh" giờ đây sau khi qua lớp Attention thì đã mang trong mình ngữ cảnh từ token "bầu" và "trời".
Nhưng khi đọc "Hôm nay bầu trời xanh quá", một người bình thường không chỉ hiểu nghĩa của câu thông qua mặt chữ, mà còn ngầm biết thêm nhiều thứ không hề được viết ra: rằng đây là một ngày đẹp trời, rằng có thể thích hợp để đi dã ngoại, rằng nhiều khả năng không cần mang theo ô. Những liên tưởng này không nằm trong bản thân câu chữ. Chúng đến từ kiến thức về thế giới mà người đọc đã tích lũy.
Vậy LLM lấy kiến thức đó từ đâu? Attention không thể cung cấp điều này, vì Attention chỉ giúp các token lắng nghe và trao đổi thông tin cho lẫn nhau trong cùng một câu. Nó không chứa bất kỳ kiến thức nào về việc "bầu trời xanh" thường đi kèm với "thời tiết đẹp". Thứ chứa kiến thức đó, và kích hoạt nó ra đúng lúc, chính là Feed-Forward Network.
FFN là kho tri thức của Transformer
Hãy nhớ lại phần kiến thức nền tảng: LLM học từ hàng triệu triệu câu trong training data, và nó mã hóa những pattern đã học được dưới dạng các con số trong những ma trận trọng số. Trong lớp Attention, chúng ta có Qw, Kw và Vw là những pattern được LLM học và mã hóa lại trong network. Tuy nhiên. phần lớn kho tri thức pattern mà LLM học được lại nằm trong FFN.
Khi LLM "biết" rằng Paris là thủ đô của Pháp, nó không lưu câu đó như một dòng chữ trong cơ sở dữ liệu. Thông tin đó được mã hóa vào trong các con số của FFN. Khi token "Paris" đi qua FFN với ngữ cảnh phù hợp, những con số đó kích hoạt và bơm thêm các thông tin liên quan vào biểu diễn của token. Đây là lý do FFN thường được ví như "bộ nhớ" của Transformer: nó là nơi mô hình tra cứu những gì nó đã học về thế giới.
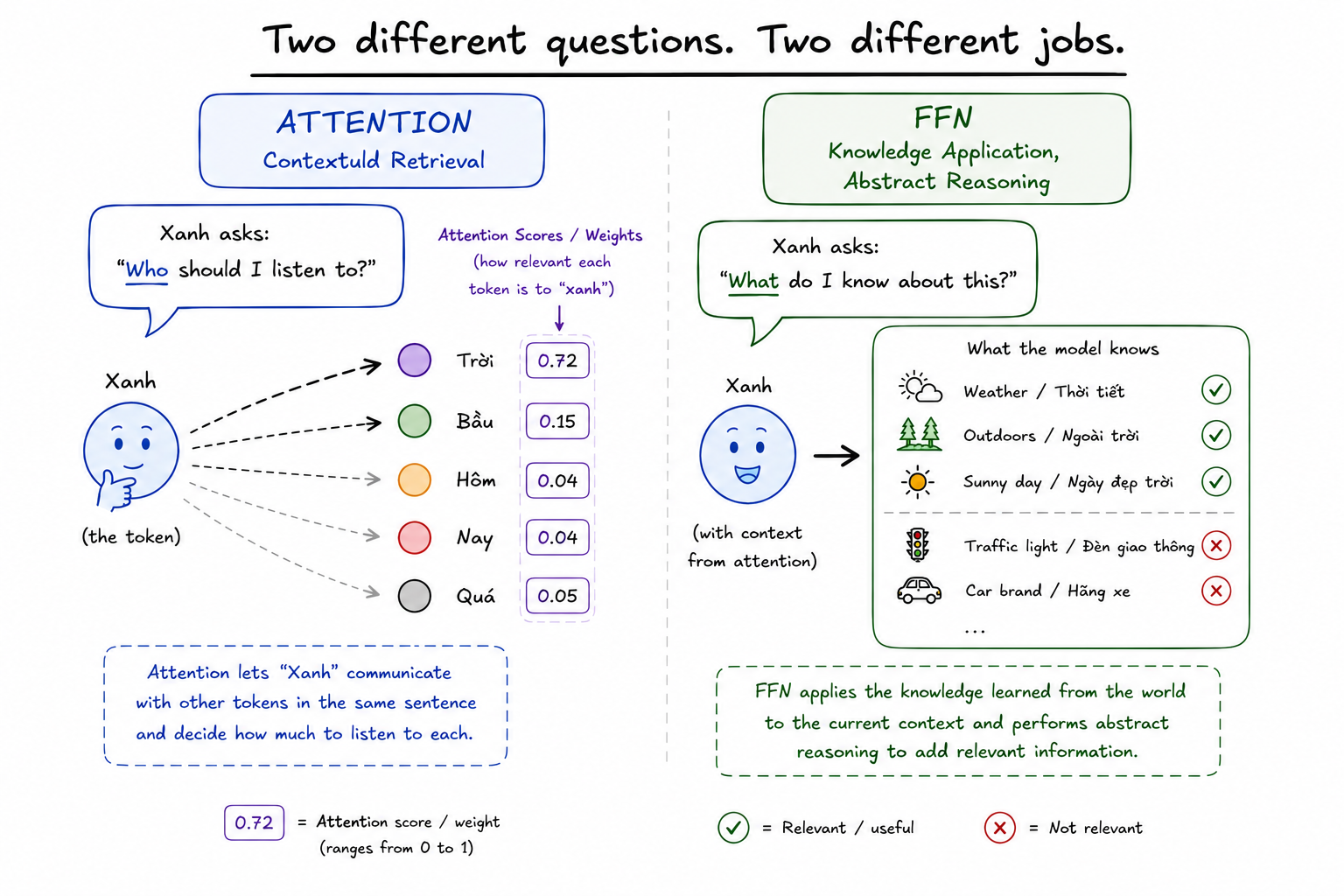
Điểm khác biệt quan trọng nhất giữa FFN và Attention nằm ở đây: trong khi Attention cho phép các token nói chuyện với nhau, FFN xử lý từng token hoàn toàn độc lập. Không có thông tin nào truyền qua lại giữa các token ở bước này. Mỗi token đi vào FFN một mình, được đối chiếu với kho tri thức, rồi đi ra với một biểu diễn giàu hơn. Nếu Attention là bước thu thập ngữ cảnh từ xung quanh, thì FFN là bước kết nối ngữ cảnh đó với kiến thức về thế giới.
FFN hoạt động như thế nào?
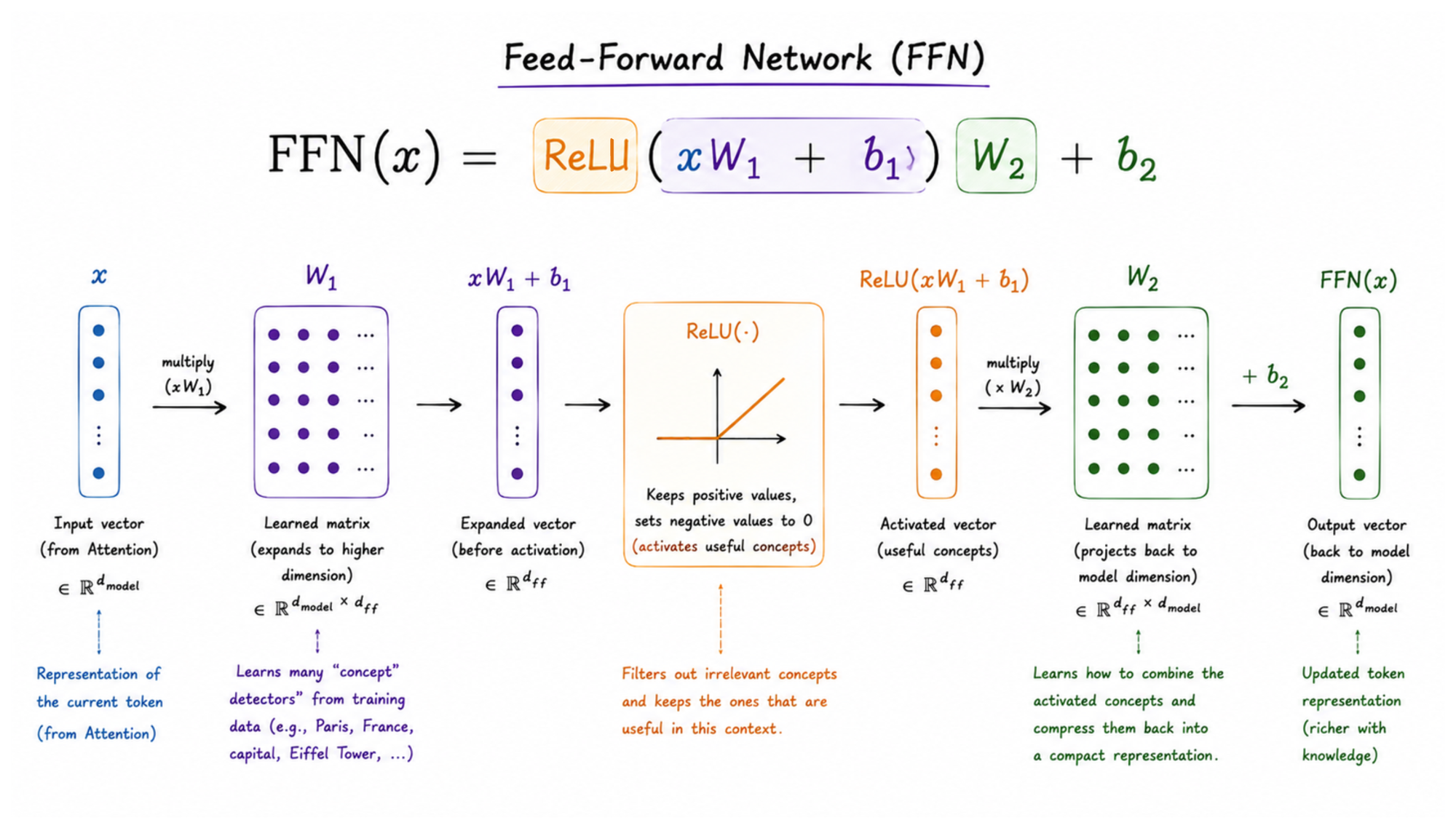
FFN thực hiện hai phép biến đổi nối tiếp nhau, thông qua hai ma trận trọng số W1 và W2. Điều thú vị là quy trình này diễn ra theo kiểu "phình ra rồi co lại": W1 mở rộng biểu diễn của token vào một không gian lớn hơn nhiều lần, rồi W2 nén nó trở lại chiều ban đầu.
Về mặt công thức toán học, nó có hình thù như sau:

Một lần nữa, nó sẽ không đáng sợ nếu bạn hiểu hòm hòm bức tranh đằng sau. Phương trình này lấy token vector đầu vào là x, nhân nó với ma trận trọng số W1 để phóng chiếu vector này lên một không gian đa chiều hơn (phình nó ra), sau đó RELU sẽ kích hoạt các khái niệm hay kiến thức liên quan, rồi sau đó nhân kết quả với W2 để nén từ không gian đa chiều về xuống lại một vector đầu ra (co nó lại).
Tại sao phải phình ra rồi co lại, thay vì biến đổi thẳng một lần?
Hãy tưởng tượng một bác sĩ nghe bệnh nhân mô tả triệu chứng. Đầu tiên, trong đầu vị bác sĩ tạm thời bật lên hàng chục khả năng cùng lúc: có thể là cảm cúm, có thể là dị ứng, có thể là dấu hiệu của thứ gì đó nghiêm trọng hơn. Đây là bước phình ra: mở rộng để cân nhắc thật nhiều khả năng. Sau đó, dựa trên các triệu chứng cụ thể, vị bác sĩ loại bỏ dần những khả năng không khớp, chỉ giữ lại số ít thực sự liên quan. Cuối cùng, tất cả được tổng hợp lại thành một chẩn đoán. Đây là bước co lại.
FFN cũng hoạt động giống như vậy với các khái niệm ngôn ngữ. W1 mở rộng biểu diễn của token để bật lên hàng nghìn "đầu dò" khái niệm cùng lúc, mỗi đầu dò chuyên nhận ra một pattern mà LLM đã học. Một hàm kích hoạt (thường là ReLU hoặc GELU) sau đó tắt đi những đầu dò không liên quan, chỉ giữ lại những pattern thực sự khớp với token đang xét. Cuối cùng, W2 nén những pattern còn lại thành một biểu diễn mới.
Nhìn lại ví dụ "xanh": sau Attention, biểu diễn của nó đã mang ngữ cảnh "bầu trời, thì hiện tại". Khi đi qua FFN, những đầu dò liên quan bật lên: trạng thái thời tiết, ngày quang đãng, không khí ngoài trời. Những đầu dò không liên quan như tên hãng xe hay màu đèn giao thông bị tắt. Output là biểu diễn "xanh" đã được làm giàu thêm một lớp kiến thức thực sự, không còn chỉ là một từ trong câu mà là một từ gắn với cả một mạng lưới liên tưởng về thế giới.
⚠️ Lưu ý: Việc FFN kích hoạt khái niệm "không khí" khi thấy token "trời" ở đây chỉ là cách diễn đạt giúp đọc giả xây dựng intuition. Thực tế, những gì LLM học được trong W1 và W2 là các con số phức tạp, và phần lớn chúng ta vẫn chưa có cách diễn dịch chúng thành ngôn ngữ của con người một cách chính xác. Hay nói cách khác, rất khó để biết được những con số nào sẽ tương quan với khái niệm cụ thể nào. Tồn tại cả một ngành gọi là mechanistic interpretability nghiên cứu về vấn đề này.
Attention và FFN phối hợp với nhau
Nhìn lại diagram kiến trúc Transformer, Attention và FFN đan xen nhau qua nhiều lớp.
- Mỗi lần đi qua Attention, các token thu thập thêm ngữ cảnh lẫn nhau.
- Mỗi lần đi qua FFN, từng token được làm giàu thêm bằng pattern LLM học được từ training data.
Qua nhiều lớp như vậy, biểu diễn của mỗi token ngày càng phong phú hơn, cho đến khi Transformer dùng biểu diễn của token cuối cùng để dự đoán token tiếp theo (phần này mình xin phép không nói chi tiết).
Mình sẽ kết thúc phần luận giải về LLM ở đây. Mình không muốn tạo ra ảo ảnh rằng đây là toàn bộ kiến thức về chủ đề này. Thực tại nó phức tạp muôn trùng. Trong thời lượng của bài viết khó mà truyền tải được hết, nên hãy xem đây là một chương dẫn nhập vào LLM. Nếu bạn được truyền cảm hứng để tự tìm hiểu thêm, thì mình đã cảm thấy thành công rồi!
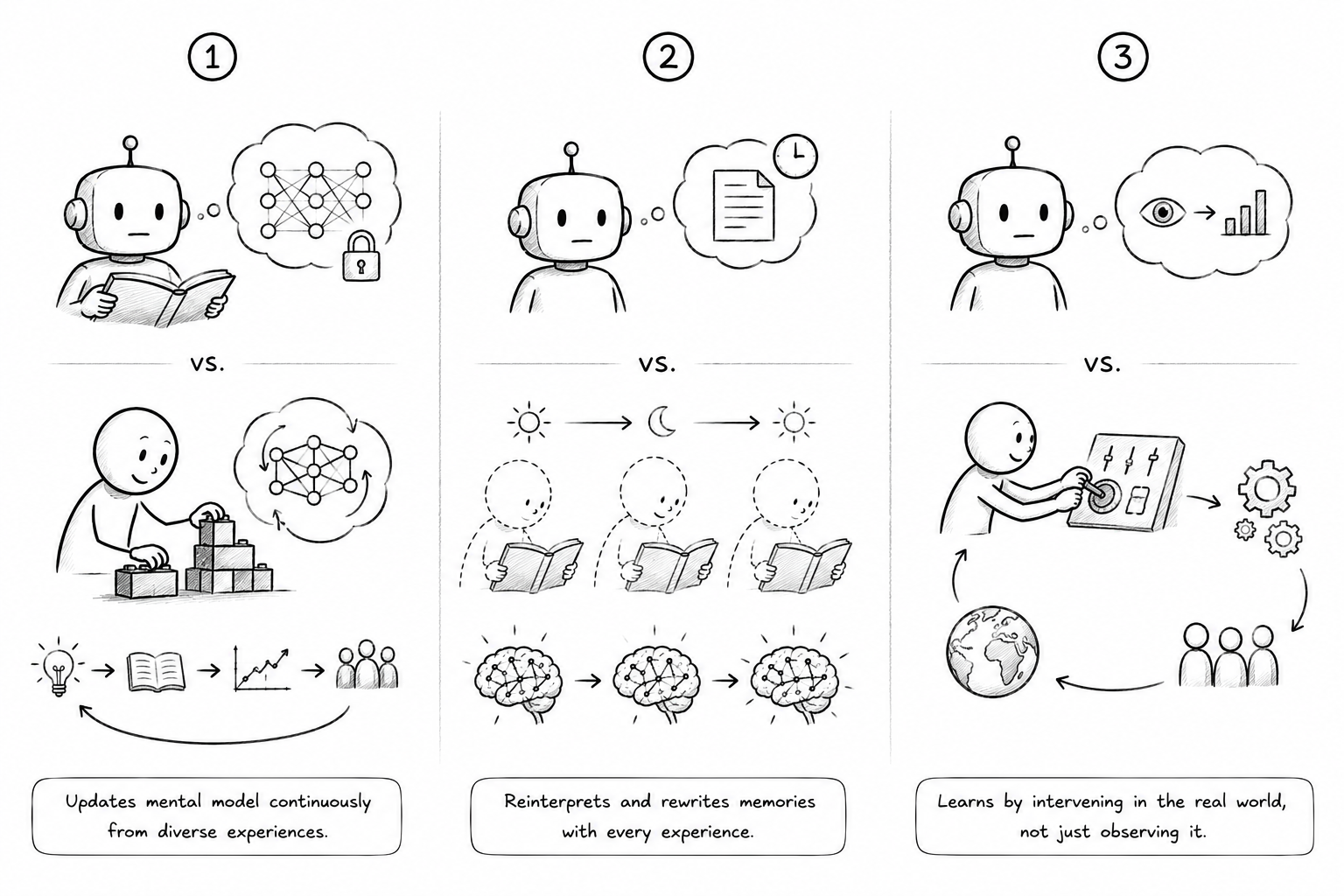
Những gì bạn vẫn có khả năng làm tốt hơn LLM
Hy vọng những kiến thức về cơ chế hoạt động của LLM sẽ giúp cho bạn tỏ tường và bớt đi nỗi sợ một chút. Trong phần này, mình sẽ phỏng đoán một vài thứ mà con người vẫn làm tốt hơn LLM, mà chủ yếu xoay quanh chuyện học.
Con người có thể cập nhật mô hình liên tục
Như đã phân tích ở trên, thông qua quá trình training, LLM mã hóa các patterns vào trong những ma trận con số khổng lồ. Một khi quá trình training đó kết thúc, những con số đó cũng bị đóng băng lại. LLM không tự học thêm bất kỳ thứ gì từ những cuộc trò chuyện nó tham gia - muốn cập nhật thì phải fine-tune lại trên dữ liệu mới, và đó là việc của các kỹ sư AI, không phải của mô hình đang chạy. Nếu là con người, điều đó giống việc bạn ngồi yên chờ đến khi ai đó dạy cho bạn kiến thức mới một cách thụ động vậy.
Nhưng đây có thể là lúc bạn đặt ra một câu hỏi hợp lý: "ChatGPT vẫn nhớ những gì tôi nói trong cuộc trò chuyện mà?" Ðúng, đây là thứ giới nghiên cứu gọi là in-context learning. Trong phạm vi một context window, LLM có thể điều chỉnh hành vi dựa trên thông tin mới nhận được. Bạn nói "Hãy trả lời ngắn hơn" và nó sẽ làm vậy - cho đến khi session đó kết thúc. Mở một tab mới, và mọi thứ reset về trạng thái ban đầu. Không có pattern gì LLM học mới từ các cuộc đối thoại đó cả.
Câu hỏi tiếp theo "Nhưng ChatGPT và Claude bây giờ có tính năng memory rồi, chúng nhớ được thứ tôi nói từ tuần trước, vậy chẳng phải nó đã học rồi sau?" Persistent memory và RAG (Retrieval-Augmented Generation) là những kỹ thuật cho phép LLM lưu lại thông tin từ các phiên trò chuyện trước rồi truy xuất chúng sau này. Về mặt kỹ thuật, chúng lưu thông tin ra một cơ sở dữ liệu bên ngoài rồi đưa thông tin đó vào context window khi cần - không có trọng số nào trong network của mô hình thay đổi.
Model không "học" theo nghĩa rằng nó đã thật sự nắm được một pattern mới và áp dụng nó khi giải quyết bài toán mới. Nó chỉ có quyền truy cập vào những ghi chú bên ngoài. Hãy tưởng tượng bạn được phép mang tài liệu vào phòng thi: quyển sách trong tay không có nghĩa là bạn đã thật sự thẩm thấu được những kiến thức trong đó, và năng lực phán đoán thực sự của bạn vẫn không thay đổi.
Điều đó dẫn đến điểm mấu chốt: kể cả khi LLM có thể nhớ được mọi cuộc trò chuyện và truy cập được vô hạn thông tin mới, nó vẫn đang tiếp nhận tất cả ở dạng ngôn ngữ, ở tầng mô tả. Những cập nhật trong mental model của con người thì hoàn toàn khác: chúng tồn tại vĩnh viễn, lan rộng sang nhiều lĩnh vực, và gắn liền với những hậu quả có thật. Khi bạn launch một sản phẩm rồi nhìn retention rụng rời trong tuần đầu tiên, không phải vì bạn chưa biết khái niệm về product-market fit mà vì bạn thật sự gánh chịu hậu quả đó, thì cập nhật nhận thức xảy ra ở một tầng sâu hơn nhiều so với những gì ngôn ngữ có thể mô tả.
Con người học từ cùng một trải nghiệm nhiều lần
Có một đặc điểm kiến trúc của Transformer mà mình thấy ít được bàn đến nhưng lại tiết lộ một giới hạn quan trọng: với cùng một đầu vào, Transformer luôn xử lý theo đúng một cách. Như đã phân tích ở phần trước, Attention và FFN đều là những phép biến đổi toán học xác định - cùng một input tokens, cùng các ma trận trọng số, cùng một kết quả tính toán. Sự ngẫu nhiên của LLM chỉ xuất hiện ở bước cuối cùng khi mô hình sample token đầu ra từ phân phối xác suất. Còn toàn bộ quá trình xử lý bên trong, từ Attention Score cho đến các khái niệm được kích hoạt trong FFN, là hoàn toàn giống nhau mỗi lần. Nếu bạn paste cùng một đoạn văn vào ChatGPT hôm nay và một năm sau, model sẽ "đọc" nó theo đúng một cách.
Con người thì không như vậy. Ký ức của con người được mã hóa trong trọng số giữa các synapse, tức là độ mạnh của các kết nối giữa các neuron, và những kết nối này thay đổi liên tục qua trải nghiệm mới, qua giấc ngủ, qua việc nhớ lại. Đây là điểm làm cho sự so sánh với LLM trở nên thú vị: LLM cũng lưu kiến thức trong các ma trận trọng số, nhưng chúng bị đóng băng sau training. Còn mạng lưới synapse của con người thì không bao giờ đóng băng. Khi bạn đọc lại một cuốn sách sau một vài tháng hay vài năm, bạn không chỉ đọc nó qua một lăng kính mới - bạn đọc nó bằng một bộ não khác. Cùng một từ ngữ kích hoạt những chuỗi liên tưởng khác nhau, chạm đến những kết nối được tạo ra bởi tất cả những gì đã xảy ra trong vài tháng hay vài năm đó.
Nhưng không chỉ vậy. Có một hiện tượng trong neuroscience gọi là memory reconsolidation mà mình thấy đặc biệt đáng chú ý. Khi bạn nhớ lại một ký ức, ký ức đó trở nên tạm thời bất ổn, mở ra để bị chỉnh sửa, trước khi được lưu trữ lại. Điều này có nghĩa là việc đọc lại một thứ gì đó không chỉ là truy xuất nó qua một lăng kính mới. Bối cảnh mới, cảm xúc mới, những liên tưởng mới tại thời điểm nhớ lại đó có thể thực sự thay đổi cách ký ức gốc được mã hóa trong não bộ của bạn. Bạn không chỉ đang truy cập hay diễn giải lại quá khứ - bạn đang viết lại nó mỗi lần quay trở lại. LLM không có cơ chế giống như vậy: không có gì thay đổi trong cách model đã "xử lý" một input trong quá khứ, vì quá trình đó không được lưu trữ theo bất kỳ hình thức nào cả.
Điều này tạo ra một lợi thế cạnh tranh mà đôi khi chúng ta không để ý: một PM nhìn lại post-mortem của một sản phẩm thất bại sau một năm không chỉ đang "ôn lại bài cũ". Với mọi trải nghiệm tích lũy trong năm đó, cùng một đoạn note kích hoạt những liên tưởng khác nhau, tiết lộ những lý do thất bại mà lần đọc đầu tiên họ chưa có đủ context để nhìn thấy. Đây là lý do mình hay journal hoặc thích đọc lại các cuốn sách hay notes cũ, vì mỗi lần như vậy mạng lưới kiến thức trong đầu không chỉ dày mà còn biến đổi để thấy được nhiều nuance hơn.
Vì vậy, việc quay lại những kiến thức "cũ" hay những bài học trong quá khứ không chỉ giúp bạn nhớ lại, mà dường như bạn phải tái cấu trúc lại kiến thức hay trải nghiệm đó, và đồng thời cập nhật lại mental model hiện tại của mình. Điều này sẽ giúp cho bạn nhìn thấy những thứ LLM khó mà thấy được từ cùng một trải nghiệm hay input.
Con người học ở tầng can thiệp, không phải tầng quan sát
Judea Pearl, người đoạt giải Turing và được xem là một trong những người đặt nền móng cho lý thuyết nhân quả hiện đại, có một framework mà mình thấy đặc biệt đắt để giải thích sự khác biệt này. Trong cuốn The Book of Why, ông chia khả năng lý luận nhân quả thành ba tầng: tầng quan sát (seeing: nhận ra tương quan giữa các hiện tượng), tầng can thiệp (doing: thực sự làm điều gì đó và quan sát kết quả), và tầng phản thực (imagining: suy luận về những gì sẽ xảy ra nếu mình đã làm khác đi). Ông gọi đây là Ladder of Causation.
LLM, về bản chất, học chủ yếu ở tầng thứ nhất: tầng quan sát. Nó đọc hàng triệu văn bản mô tả mối quan hệ nhân quả: "Startup X thất bại vì thiếu product-market fit", "Công ty Y tăng trưởng nhờ network effect." Nó mã hóa được những patterns nhân quả đó vào network. Nhưng nó không bao giờ thật sự launch một sản phẩm, không bao giờ cảm nhận áp lực khi OKR sắp bị miss, không bao giờ phải ngồi trong một cuộc họp với leadership và giải thích tại sao các con số đang đi sai hướng. LLM biết về nhân quả vì ngôn ngữ của loài người mô tả mối quan hệ nhân quả, không phải từ việc thực sự nằm trong chuỗi nhân quả đó.
Ðây là điều tạo ra sự khác biệt về chất lượng phán đoán, không chỉ về lượng thông tin. Một PM đã từng ship ba sản phẩm thất bại không chỉ có "nhiều case study về thất bại hơn" trong đầu so với LLM. Họ có một loại hiểu biết khác hẳn về product-market fit mà không thể đạt được chỉ qua đọc. Khi LLM đọc post-mortem của một startup, nó học được những gì người viết đã articulate được sau khi nhìn lại. Còn người PM kia biết những thứ không ai viết ra: sự im lặng trong phòng họp trước khi mọi người nhận ra sản phẩm không ổn, cái intuition hình thành sau khi buổi user testing thứ ba liên tiếp kết thúc mà không ai tìm thấy feature nào để thật sự hào hứng về.
Nhưng điều quan trọng nhất ở đây không phải là câu chuyện về quá khứ, mà là hàm ý cho tương lai. Vì con người học ở tầng can thiệp, chúng ta có thể tích lũy loại trí tuệ mà LLM không thể sao chép được, dù được training thêm bao nhiêu dữ liệu đi nữa.
Nhìn theo góc độ này, không có gì thật sự là "thất bại" cả trong công cuộc giúp bạn xây dựng lợi thế cạnh tranh so với LLM. Mỗi kết quả ngoài mong đợi, mỗi sản phẩm không ai dùng, mỗi quyết định sai đều là dữ liệu ở tầng can thiệp mà LLM không bao giờ tiếp cận được. Bạn không chỉ học từ những hậu quả đó - bạn đang tích lũy chính xác loại tín hiệu mà không một lượng training data nào trên thế giới có thể tạo ra.
Kết luận
Tóm tắt lại bài viết, thì có một số ý quan trọng:
- LLM hay cụ thể là Transformer sử dụng cơ chế Attention để các tokens trao đổi thông tin với nhau, sau đó dùng FFN để áp dụng kiến thức, khái niệm, các mô hình nhân quả để làm dày hơn ý nghĩa của các tokens.
- Hai cơ chế này đan xen, output của một lớp là input của lớp tiếp theo, rồi các token vectors sẽ được biến đổ thành các dạng bao hàm đầy đủ ý nghĩa nhất mà LLM có thể làm được, và cuối cùng từ đó dự đoán token tiếp theo.
- Con người học theo một cơ chế mà LLM, về cấu trúc, không thể thực hiện được. Mental model cập nhật liên tục từ những tín hiệu có rủi ro và hậu quả thực sự, không phải từ ngôn ngữ mô tả hậu quả, mà từ việc trực tiếp gánh chịu chúng.
- Trải nghiệm trong quá khứ không phải là file tĩnh, bởi mạng lưới synapse thay đổi liên tục khiến cùng một input sinh ra ý nghĩa mới mỗi lần ta quay trở lại với nó.
- Và con người học ở tầng can thiệp theo Ladder of Causation của Pearl, không phải chỉ quan sát pattern từ xa mà trực tiếp tham gia vào chuỗi nhân quả rồi học từ phản hồi của thế giới thực. Ba cơ chế này tạo ra loại năng lực mà không một lượng training data nào có thể thay thế được.
Chuyện học sâu vốn dĩ luôn là quan trọng, nhưng trong thời đại này thì mình nghĩ càng quan trọng hơn nữa, vì đó là một trong những thứ con người vẫn đang làm tốt được hơn AI. Tuy nhiên, thế giới ngày nay tồn tại muôn vàn những thứ cướp lấy sự tập trung, tâm trí và động lực của chúng ta. Từ smartphone, mạng xã hội đến tiktok đều là đang khiến con người mất đi sự sáng suốt. Nếu bạn muốn kiến tạo và duy trì lợi thế cạnh tranh của mình trong thời đại AI, hãy cố gắng đầu tư xây dựng thói quen, môi trường và thời gian cho bản thân mình có thể học tập tốt.
Nếu ví AI giống như màn đêm tăm tối đầy ắp sự bất định, và loài người phát minh ra lửa là một sự kiện thay đổi quỹ đạo phát triển của nhân loại, thì bài viết này của mình chỉ là một nỗ lực tạo ra tia lửa le lói, hy vọng giúp mọi người nhìn thấy được những thứ nằm đằng sau bức màn AI đó rõ hơn một chút. Đừng vội tin những thứ mình viết ở đây, mà hãy tự tò mò, nghiên cứu và tự có cho mình một thế giới quan về việc bản thân bạn nên làm gì để có lợi thế cạnh tranh so với AI.



